
The latest major release of the open-source search and analytics suite, OpenSearch 3.2, is now generally available. Packed with performance upgrades, new data types, and richer tooling for search and observability, this update strengthens the platform’s ability to serve modern, data-heavy applications—especially those powered by generative AI and machine learning.
Whether you’re building intelligent search experiences or monitoring complex distributed systems, OpenSearch 3.2 brings tangible improvements that enhance efficiency, scalability, and precision. Below, we break down what’s new, why it matters, and who stands to benefit the most.
What is OpenSearch 3.2?
OpenSearch is an open-source search and analytics engine derived from Elasticsearch 7.10.2 and developed under the stewardship of AWS and the broader open-source community. The 3.2 release continues the trajectory set by earlier 3.x versions, introducing optimizations and features that make it a stronger competitor to commercial solutions.
Designed to handle large-scale search, logging, and analytics workloads, OpenSearch 3.2 enhances its core capabilities to better support use cases involving AI, such as semantic search, retrieval-augmented generation (RAG), and real-time observability. It offers a community-driven, flexible alternative for developers and enterprises looking for full control over their search and data analytics infrastructure.
What’s New in OpenSearch 3.2?
1. Improved Search Performance and Scalability
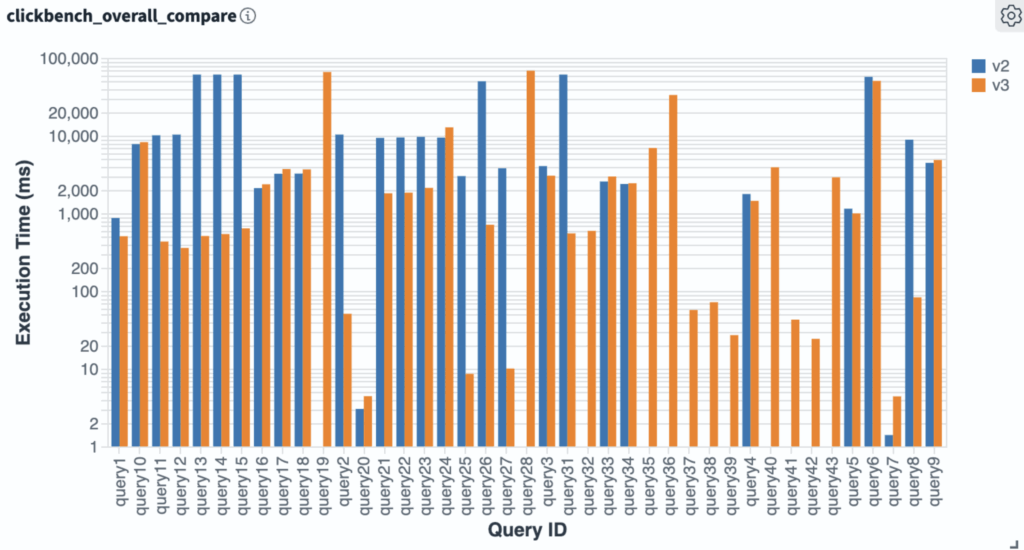
A key highlight of OpenSearch 3.2 is the enhanced support for search_after queries in its Approximate K-Nearest Neighbors (KNN) framework. This reduces performance bottlenecks commonly encountered in deep-pagination scenarios, making it ideal for applications that require scrolling through large ranked result sets.
The update also improves sorting performance on time-series and numeric fields. By optimizing BKD-tree traversal, OpenSearch significantly cuts down query latency and speeds up data retrieval. Benchmark tests confirm noticeably faster response times, which is critical for real-time dashboards and applications that rely on rapid data access.
Another performance booster is the new skip_list feature. It allows the query engine to skip non-matching document ranges more efficiently, leading to faster query execution—especially when filtering large datasets.
2. More Robust Analytics with Enhanced Aggregations
OpenSearch 3.2 expands its analytical power with star-tree aggregations that now support IP fields. This is particularly useful for network and security analytics, where IP addresses are central to log analysis and threat detection.
New statistical metrics linked to these aggregations offer deeper insights and more flexible reporting options.
3. Supercharged Vector Search for AI Applications
As generative AI and large language models (LLMs) continue to reshape technology, efficient vector search has become essential. OpenSearch 3.2 answers this demand with broader GPU support and higher-quality vector search capabilities.
New vector data types—including FP16 (half-precision float), byte, and binary—help reduce memory footprint and improve resource efficiency. This is especially valuable for applications that need to store and search billions of embeddings, such as content recommendation engines or multimedia retrieval systems.
The release also introduces asymmetric distance computation and random rotation techniques, which work in tandem with improved HNSW graph algorithms to deliver more accurate and reliable similarity search. These advances make it easier to build high-precision semantic search and RAG pipelines.
4. Enhanced Observability and Log Analytics
For developers and SREs focused on system monitoring, OpenSearch 3.2 strengthens its observability suite with native support for OpenTelemetry in the Trace Analytics plugin. This simplifies integration with existing instrumentation and provides a standardized approach to distributed tracing.
The Piped Processing Language (PPL) has also been updated for better query flexibility, performance, and correctness. These enhancements streamline the process of parsing and analyzing large-scale log data, enabling more sophisticated transformations and real-time diagnostics.
Who is OpenSearch 3.2 Best For?
- AI and ML Engineers: Developers building semantic search, recommendation systems, or RAG-based applications will benefit from the more efficient vector storage and improved accuracy of nearest-neighbor search.
- DevOps and SRE Teams: The bolstered observability features—including OpenTelemetry support and refined PPL capabilities—help teams monitor service health, troubleshoot performance issues, and maintain system reliability.
- Data Analysts and Security Researchers: With improved aggregations for IP fields and better support for statistical metrics, OpenSearch 3.2 is well-suited for network traffic analysis, security event investigation, and business intelligence.
- Enterprises and Startups Alike: The reduced memory overhead and increased query efficiency make this release a cost-effective solution for organizations of all sizes managing large and growing datasets.
Conclusion on OpenSearch 3.2 Release
OpenSearch 3.2 marks a meaningful step forward in the platform’s evolution. By honing in on vector search performance, query efficiency, and observability integration, it positions itself as a compelling open-source solution for next-generation search and analytics applications.
This release reflects the project’s commitment to serving the growing needs of the AI and data communities—all while maintaining the openness and flexibility that users expect from a community-driven project.
Whether you’re upgrading from an earlier version or considering OpenSearch for the first time, version 3.2 offers a powerful, scalable, and future-ready foundation for building intelligent data experiences.
Read More: Google Launches Gemma 3 270M


