Meta’s research team has now open-sourced Meta AU-Nets (Autoregressive U-Nets), Meta AU-Nets is a revolutionary token-free language model that processes raw UTF-8 bytes, eliminating traditional tokenization. Its U-Net-inspired architecture delivers linear computational efficiency, 20-30% faster inference, and superior multilingual performance – especially for low-resource languages. Open-sourced under MIT license, this scalable model (1B-8B params) simplifies AI workflows from training to deployment, marking a significant leap in efficient, multilingual NLP.
1. What is Meta AU-Nets?
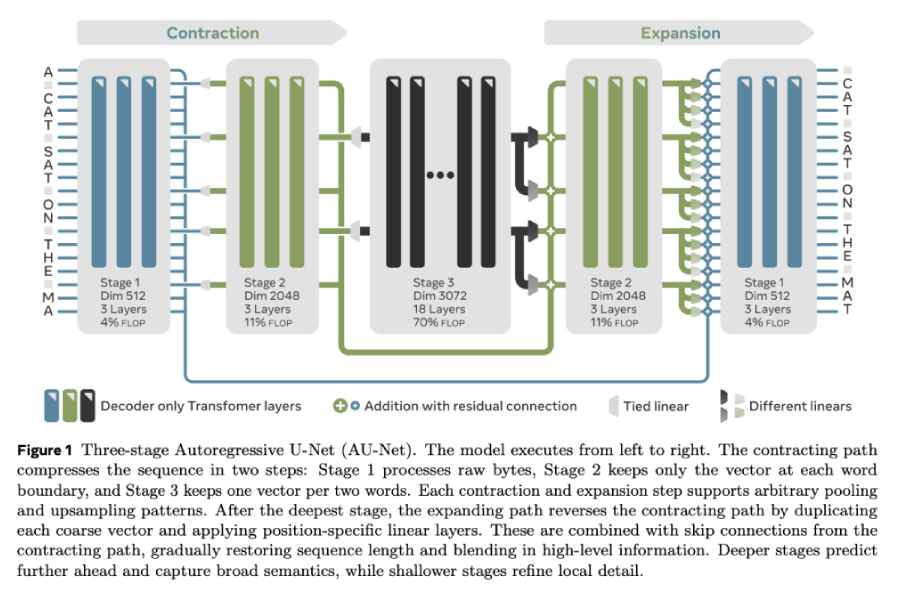
AU-Nets borrows the encoder-decoder “compress-expand” design of U-Net, originally created for medical imaging, and adapts it to language. Three architectural decisions set it apart:
– Token-free: The model sees UTF-8 bytes directly, eliminating vocabulary bias and easing support for low-resource scripts.
– Linear complexity: Layer-wise convolutions plus parallel decoding keep FLOPs proportional to sequence length, giving large gains on long documents.
– Multi-scale learning: Bytes are dynamically grouped into words, bigrams, and four-gram blocks during compression; the decoder then restores detail, balancing global and local context.

2. Meta AU-Net Core capabilities and benchmarks
Meta AU-Net performs competitively across standard tasks:
– Multilingual translation: On FLORES-200, the 8 B-parameter model scores 43.3 BLEU, beating same-size Transformers and showing strong lift on Swahili and other low-resource languages.
– Long-context modelling: On PG-19 the model reaches 2.61 bits/byte, outperforming Transformer’s 2.75.
– Inference speed: Parallel decoding yields 20–30 % faster generation than autoregressive baselines, making the model suitable for real-time applications.
– Scalability: Parameters can be tuned from 1 B to 8 B, with stable improvements when training data grows from 60 B to 200 B tokens.

3. How to use Meta AU-Nets for developers
Environment
Code is released under the MIT licence on GitHub and requires PyTorch 2.1+.
– 1 B model: 8 GB GPU memory in FP16.
– 8 B model: 40 GB GPU memory or DeepSpeed ZeRO-3 recommended.
Minimal usage
from au_net import AUModel
model = AUModel.from_pretrained("meta/au-net-1B")
output = model.generate("The quick brown fox".encode(), max_new_bytes=64)
print(output.decode()) # direct UTF-8 decodingTraining & fine-tuning
Data Preparation
A key advantage ofMeta AU-Net is its ability to process raw text bytes directly, eliminating the cumbersome tokenization preprocessing required by traditional models. Developers only need to ensure that input data is in UTF-8 encoded plain text files (e.g., .txt or .json formats), with no additional handling needed for punctuation, capitalization, or rare characters. For example, even multilingual text mixing Chinese, Arabic, and emojis can be parsed directly by the model at the byte level. This feature significantly reduces data cleaning overhead, making it particularly suitable for building cross-language unified models.
Single-GPU Training Configuration
For research teams with limited resources, the 1B-parameter version of AU-Net can be fine-tuned efficiently on a single A100 GPU (40GB VRAM):
- Hardware Requirements: It is recommended to use an A100 with PCIe 4.0 or higher to fully utilize NVLink bandwidth.
- Training Efficiency: With mixed-precision training (FP16) on 10GB of domain-specific data (e.g., medical literature or legal texts), fine-tuning can be completed within 24 hours, with a suggested learning rate of 3e-5.
- VRAM Optimization: If VRAM is insufficient, enabling gradient checkpointing and DeepSpeed’s ZeRO-2 stage can reduce memory usage by 30%.
Production Deployment
Meta provides a complete deployment toolchain for AU-Net:
- Triton Inference Server: Supports dynamic batching and concurrent requests, achieving millisecond-level latency in Kubernetes clusters. For example, an 8B model running on 4xA100 nodes can handle over 200 generation requests per second (input length ≤512 bytes).
- Quantization: With 8-bit integer quantization (INT8), model size is reduced by 4x, VRAM requirements drop by 60%, and the BLEU score on FLORES-200 translation tasks decreases by only 0.3 (from 43.3 to 43.0). The quantized model can even run smoothly on consumer-grade GPUs like the RTX 3090.
- Performance Monitoring: Built-in Prometheus metrics export enables real-time tracking of throughput, VRAM usage, and generation quality for easy operational adjustments.
These design choices make AU-Net highly efficient from experimentation to deployment, especially for commercial scenarios requiring rapid iteration.
With Meta AU-Nets, Meta is proposing a new foundation-model paradigm: token-free, compute-efficient, multilingual by default. The weights and training scripts are already available, letting practitioners test the architecture today in translation, summarization, and any other text-generation task.


